Project Abstract
This project presents a novel, learned variant of the Perona-Malik anisotropic diffusion process. By unrolling the classical Partial Differential Equation (PDE) into a neural network architecture, we replace hand-designed conduction functions with a spatially-adaptive conduction network. Our model incorporates a MiniUNet guidance encoder and an 8-neighbor diffusion mode to effectively suppress noise while preserving critical anatomical edges. Evaluated on the Br35H dataset, our Unified Neural PDE model achieved a PSNR of 24.85 dB, outperforming the best classical baseline by +4.46 dB.
Interactive Results Explorer
Switch between the final comparison, U-Net baseline, noise robustness sweep, and ablation suite.
Methodology
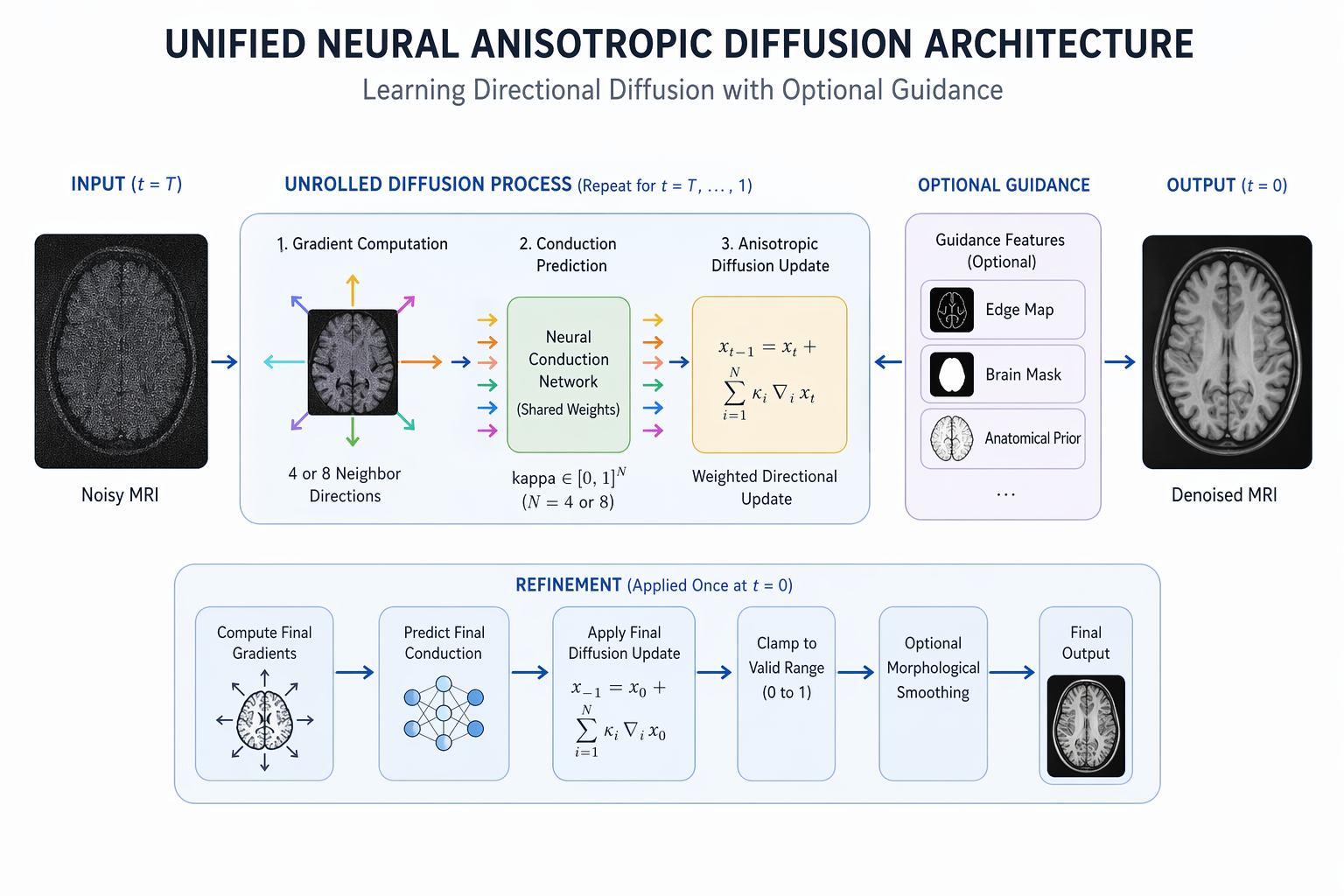
Neural PDE Architecture
The model unrolls the diffusion process into iterative steps. At each step, a Conduction Network predicts spatially varying diffusion weights for 8 neighboring pixels.
A MiniUNet guidance encoder provides global context to the diffusion process, while a final residual refinement stage recovers fine details smoothed by the PDE.
Updated architecture diagram for the unified neural PDE model.
Hybrid Loss Function
The model is trained using a composite loss that prioritizes both structural fidelity and edge sharpess.
- SSIM Loss: Preserves global structural similarity.
- L1 Loss: Ensures pixel-level fidelity.
- Gradient Loss: Penalizes blurring of anatomical boundaries.
The Gradient loss is critical for ensuring the denoiser doesn't wash out small lesion margins or cortical edges.
Qualitative Analysis

Multi-Method Comparison
Visualizing the denoising performance across classical filters and neural approaches. Our model (Neural PDE) preserves contrast and edges significantly better than the hand-designed baselines.
Discussion & Conclusion
Interpretability
Unlike "black-box" CNNs, our model follows a physical diffusion process. By inspecting the conduction weights, we can verify that the model is intelligently stopping diffusion at detected edges, matching the inductive bias of classical medical imaging.
Conclusion
The project demonstrates that learned anisotropic diffusion bridges the gap between classical PDEs and deep learning. It achieves massive gains over traditional filters (+4.4 dB PSNR) while remaining structured and interpretable.